Une DApp native est une application native qui interagit avec un Smart Contract déployé sur une BlockChain. Dans le post précédent nous avons défini des principes d’architecture qui permettent d’avoir un niveau acceptable de sécurité et de user experience. Dans cette partie, nous rentrerons dans le code Android qui permet à cette DApp native de fonctionner.
Développer une Application Blockchain sur Android – Partie 1
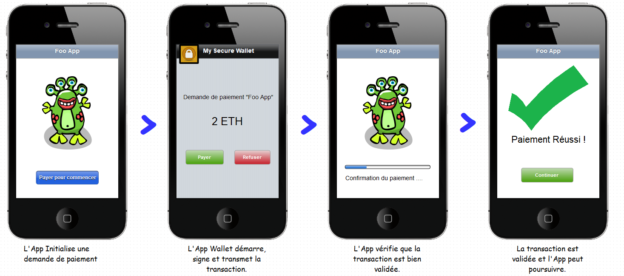
Ce poste vient comme suite logique à deux premiers posts pour créer un Smart Contract pour Ethereum et le deployer sur un testnet , je voulais créer une DApp Native : une application sous Android qui permettrait d'utiliser ce contrat de façon intuitive.
Deployer un Smart Contract sur Ropsten un testnet d’Ethereum
Dans mon post précédent j'avais exposé les étapes pour développer et tester un Smart Contract du prêt solidaire Daret dans l'IDE REMIX. L'objectif maintenant est de le deployer sur une vraie blockchain. C'était plus facile que je ne croyais.
Pas à pas : créer un Smart Contract pour la blockchain Etherium
On dit que les cryptomonnaies pourraient rendre service aux non bancarisés, du coups pour des premiers pas sur la blockchain j'ai implémente en Smart Contract pour Daret, un prêt solidaire qui se base sur un principe simple : chaque participant paye une somme fixe chaque mois, et, à tour de rôle, chacun parmi les participants reçois la somme totale collectée pendant le mois.
Elements d’un projet EMS
Un projet EMS est d’abord un projet informatique, il convient donc de respecter pour ce type de projets les démarches et jalons classiques du recueil des besoins à la recette. Ceci dit, au vu de l’architecture et de la nature d’un EMS, ces quelques lignes attirent l’attention sur quelques spécificités des projets EMS auquelles il est important de faire attention.
Architecture technique d’un Système EMS
L'objectif d'un EMS est d'optimiser l'utilisation d'énergie de systèmes phyisques, un EMS est donc toujours une brique logicielle qui doit interagir avec le monde réel pour former un "cyber-phyisical-system". Dans ce type de systèmes l'interaction entre le logique et physique se fait à travers deux types d'interfaces : les capteurs et les actuateurs. Les premiers remontent une information (ex. consommation instantannée d'énergie) à partir d'un objet physique vers un programme, Les seconds appliquent physiquement les consignes d'un programme (ex. arrêter / mettre en marche un climatiseur).
Comment utiliser son logiciel de gestion d’energie pour : maitriser sa facture électrique, l’optimiser puis saisir les nouvelles opportunites
La mise en oeuvre d'un logiciel de gestion d'energie (EMS) a pour but d'optimiser l'utilisation de l'énergie et mieux réagir à sa facture électrique. Qu'entend-t-on par "optimiser l'utilisation de l'énergie" ? Pour répondre, nous avons distingué 3 niveaux : Comprendre et maîtriser sa facture, Optimiser sa consommation et enfin saisir les nouvelles opportunités. Pour chaque niveau nous détaillons les fonctions clé du logiciel EMS qui permettent de l'atteindre.
Gestion d’énergie en entreprise, au delà de payer sa facture : savoir y réagir
La production électrique prends une part de plus en plus importante dans le mix énergétique mondial comme énergie finale au moment même où il devient nécessaire aux producteurs d'abandonner des sources classiques pour des sources plus propres et durables. Dans ce contexte, il devient nécessaire d'impliquer les consommateurs industriels et privés pour maintenir l'équilibre la production/consommation. Cela se traduit par le signal-prix, ou plus simplement dit, à travers la facture d'électricité.
Energy Management Systems, logiciels et démarches
Energy Management System (EMS) peut faire référence soit à des démarches organisationnelles d’optimisation de la gestion de l’énergie soit aux logiciels et systèmes informatiques permettant de mettre en oeuvre ces démarches.
Recrutement et rétention d’éducateurs en milieu rural
La qualité de l'enseignant est considérée comme un élément clé de la réussite scolaire des élèves, or recruter et retenir des éducateurs de qualité dans les milieux ruraux victimes d'éloignement et de pauvreté est un challenge. L'objet de ce billet est de synthétiser des éléments de la littérature académique abordant les difficultés de recrutement et de rétention d'éducateurs en milieu rural. Afin de se faire une idée plus claire de l'ampleur du défi et partager des expériences pour inspirer une action et des choix efficaces.